


Qual é a distância entre o galego e o português?
O galego e o português estão próximos. Será possível quantificar essa proximidade? E como medir a distância entre o português de agora e o português de Camões?


Este artigo é uma adaptação de um capítulo do livro História do Português desde o Big Bang.
Como medir a distância linguística?
Haverá forma objectiva de olhar para a proximidade entre línguas ou variantes de línguas? Não é fácil: todos temos tendências, impressões, inclinações…
Há, no entanto, técnicas que tentam ser um pouco mais objectivas. Um dos mais recentes estudos neste âmbito foi realizado por José Ramom Pichel, numa investigação apresentada nos artigos científicos referidos na bibliografia e na sua tese de doutoramento. (Fui co-autor, em conjunto com outros linguistas, de dois dos artigos.)
O estudo baseia-se neste facto linguístico: um conjunto de caracteres aparece com uma frequência diferente entre línguas, mas é relativamente estável em textos da mesma língua.
Todos concordarão, por exemplo, se eu disser que «ção» é um conjunto de caracteres muito frequente em textos escritos em português e muitíssimo pouco frequente em textos escritos em castelhano (por exemplo). Mais do que isso: a frequência com que aparece num texto português é relativamente estável.
Se olharmos e contabilizarmos as frequências de conjuntos de caracteres com dimensão suficiente, encontramos uma espécie de impressão matemática de cada língua. Por exemplo, «ção#de#» (# representa o espaço, que também é usado para estes cálculos) é um conjunto de 7 caracteres com uma determinada frequência em português. Este conjunto denomina-se, tecnicamente, «7-grama». A elevada frequência deste 7-grama depende do facto de a preposição «de» poder seguir-se a um nome, sendo esta uma construção frequente.
O conjunto de frequências dos 7-gramas de determinado corpus (conjunto de textos) representativo de uma língua ou variante cria uma impressão matemática não só do léxico, como da morfologia das palavras e da própria sintaxe da língua.
Uma análise matemática destas frequências será cega: ninguém ensina à fórmula matemática o que é uma preposição ou um nome; no entanto, o próprio funcionamento da língua implica as tais frequências, que ficam assim impressas nos números analisados. A própria cegueira da matemática ajuda-nos, neste caso, a limpar impressões e tendências pessoais.
José Ramom Pichel usou uma métrica ainda mais complexa do que a descrição acima − essa métrica já existia e tem como nome perplexity. Em termos simples, mede a distância de um texto (ou conjunto de textos) em relação a um modelo de língua previamente calculado com base num corpus significativo (com milhões de palavras dessa língua).
A métrica foi adaptada à análise da proximidade linguística, criando-se um valor de PLD (Perplexity Language Distance) que mede a distância entre, por exemplo, português e castelhano, português e russo ou inglês e arménio − mas também entre português europeu e português do Brasil ou castelhano de Espanha ou castelhano da Argentina.
Proximidades e distâncias das línguas da Europa
Quanto mais baixa a PLD, mais próximas as línguas ou variantes.
Se calcularmos a PLD entre textos na mesma língua e variante surge-nos um valor próximo do 3 (a PLD só será 0 se usarmos os mesmos textos para criar o modelo de língua e o corpus de teste).
Entre variantes da mesma língua, costumamos encontrar valores entre o 3 e o 6.
Entre línguas próximas, encontramos valores de PLD entre o 6 e 12 (a distância entre português e castelhano é de aproximadamente 8).
Entre línguas distantes encontramos valores muito superiores: entre inglês e holandês temos 31 e entre o inglês e o francês temos 16 (que o inglês esteja muito mais próximo do francês do que de uma língua germânica vizinha mostra bem os estragos que o francês fez à língua para lá da Mancha).
Os valores entre o 5 e o 7 são interessantes, pois aparecem no caso de línguas em que a diferença entre língua e variante é ténue − a PLD entre bósnio e croata é de 5 e a PLD entre galego e português é de 6 (a PLD entre galego e castelhano também é de 6). Por comparação, a PLD entre catalão e castelhano é de 8, igual à PLD entre português e castelhano. Outras línguas próximas revelam valores superiores. O sueco e o dinamarquês apresentam uma PLD de 13.
Aplicando esta técnica às línguas da Europa, encontramos um mapa de proximidades:
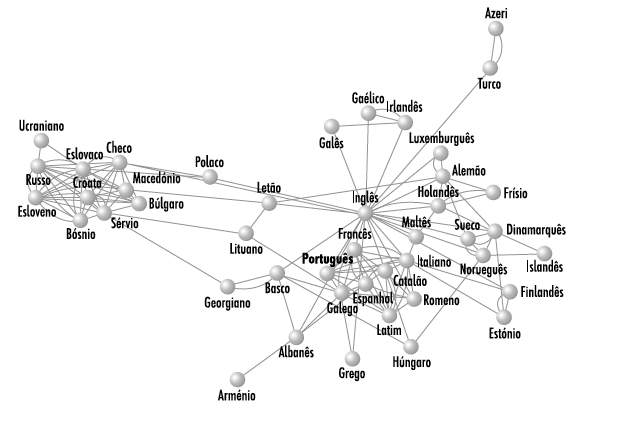
Mapa de distâncias entre línguas na Europa, com base em PLD. Adaptação de imagem incluída no artigo de Pablo Gamallo, José Ramom Pichel e Iñaki Alegria, «From Language Identification to Language Distance».
Apesar de algumas distorções em relação à origem das línguas − a especial inclinação do inglês para as línguas latinas, a proximidade do maltês (uma língua semítica) ao italiano, entre outras − este mapa mostra de forma bastante certeira o agrupamento de línguas por famílias. Esta adequação não foi previamente incluída nas fórmulas usadas para os cálculos − surge naturalmente da análise nos textos. Temos, assim, uma forte indicação de que esta métrica é adequada para estudar a proximidade entre línguas.
Duas notas importantes: estes cálculos baseiam-se em textos escritos e publicados. São, portanto, um cálculo da proximidade entre normas. Em segundo lugar, para conseguirmos perceber até que ponto as diferenças ortográficas interferem nos resultados, os cálculos foram feitos duas vezes: com a ortografia dos textos tal como existe na realidade (original) e com uma ortografia normalizada, que permite comparar a distância entre épocas e variantes independentemente da ortografia (transcrito).
O português mudou muito ao longo da História?
Esta métrica permite comparar diferentes épocas da língua, para perceber a distância que a língua percorreu. Assim, se usarmos textos do final do século XX e calcularmos a distância em relação a várias épocas históricas do português, encontramos os seguintes valores:

Em cada época, a barra da esquerda representa a distância usando textos com a ortografia original e a barra da direita com uma ortografia artificial, normalizada entre épocas. A distância entre o português do final do século XX e o português da época medieval está, se ignorarmos a ortografia, no nível 6.
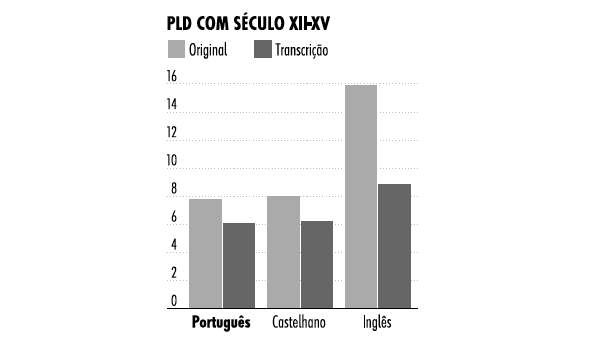
Será que esta diferença em relação à época medieval é grande ou pequena? Sem compararmos com outras línguas, não saberemos. Como termo de comparação, apresento os mesmos cálculos para o castelhano e para o inglês:


O gráfico castelhano parece seguir uma tendência muito semelhante à tendência do gráfico português. Já o gráfico do inglês é muito diferente. A distância entre o inglês do final do século XX e o inglês da época medieval é muito superior ao que acontece no português e no castelhano. Usando o mesmo eixo vertical, verificamos claramente a diferença e percebemos ainda que a ortografia tem mais importância para a análise no caso do inglês:
Dança a três
Olhemos agora para a relação entre o português, o galego e o castelhano. Será que a proximidade foi sempre a mesma?

No primeiro período de análise, o galego e o português estavam muito próximos. Entre a Idade Média e o século XIX, afastaram-se. Não é surpresa. Entre os dois períodos, tanto o castelhano e o português como o castelhano e o galego aproximaram-se.
Como explicar esta aproximação entre o castelhano e as duas línguas a ocidente, mas o afastamento entre estas duas últimas? Provavelmente, o próprio castelhano influenciou ambas, mas em sentidos diferentes. Aproximou-se do português e aproximou-se do galego, mas através da influência de diferentes palavras e construções, criando um afastamento entre galego e português. Sublinhe-se que o abraço castelhano ao português terá sido anterior ao abraço castelhano ao galego.
O português e o castelhano afastaram-se marcadamente na primeira metade do século XX e voltaram a aproximar-se (ligeiramente) na segunda metade do mesmo século. Entretanto, o galego e o português estão num lento processo de aproximação, que também se nota entre galego e castelhano. É possível que estas aproximações se devam a uma aproximação geral das várias línguas da Europa (sujeitas a influências comuns e a uma crescente padronização da linguagem técnica e científica), mas terá de haver mais estudos de medição de PLD para verificar se tal é o caso.
O galego parece encurralado entre duas línguas − é difícil encontrar línguas mais próximas que o português e o galego, mas o mesmo se pode dizer do galego e do castelhano. Conhecendo nós a origem comum do galego e do português e o facto de o galego ser falado num Estado em que o castelhano é a língua dominante, compreende-se que esta situação tenha dado origem a um conflito linguístico e político. Se sairmos dos textos e andarmos pela rua, percebemos que o abraço castelhano ao galego é, hoje, tão forte que está em vias de sufocar o abraçado… Para vermos tal aperto, teríamos de olhar para a oralidade (principalmente nas cidades) e para os textos informais, algo que o estudo que estou a descrever, para já, não faz.
Note-se que os números não respondem à famosa pergunta: o galego e o português são a mesma língua? Essa resposta somos nós, falantes, que a temos de dar — e não uma qualquer fórmula matemática. No entanto, percebemos claramente que o galego e o português estão muito próximos, mesmo quando olhamos para as normas – que foram construídas de costas voltadas. Se, para lá da norma, olharmos para a variação interna, encontraremos, além da proximidade, várias continuidades — basta andar a pé entre aldeias a sul e a norte da fronteira para perceber isso mesmo.
De todos os dados apresentados, destaco o seguinte: na escrita, a distância entre o português actual e o português do tempo de Camões é apenas ligeiramente inferior à distância, na actualidade, entre o galego e o português. Aproveitemos a proximidade — afinal, se conseguimos ler Os Lusíadas, também conseguimos ler em galego.
Referências
O texto acima foi retirado (com adaptações) do livro História do Português desde o Big Bang (Capítulo 10), que também mostra os resultados da comparação entre o português de Portugal e o português do Brasil e entre o castelhano de Espanha e o castelhano da Argentina. As infografias são de Nuno Costa.
Os artigos científicos que descrevem a investigação apresentada são os seguintes:
Gamallo, Paulo & José Ramom Pichel & Iñaki Alegria. “From language identification to language distance”. In Physica A: Statistical Mechanics and Its Applications 484, 152-162, 2017.
Pichel, José Ramom & Paulo Gamallo & Iñaki Alegria & Marco Neves. “A Methodology to Measure the Diachronic Language Distance between Three Languages Based on Perplexity”. In Journal of Quantitative Linguistics, 1-31, 2020. DOI: 10.1080/09296174.2020.1732177
Pichel, José Ramom & Paulo Gamallo & Iñaki Alegria. “Cross-lingual Diachronic Distance: Application to Portuguese and Spanish”. In Procesamiento del Lenguaje Natural 63, 77-84, 2019.
Pichel, José Ramom & Paulo Gamallo & Iñaki Alegria. “Measuring diachronic language distance using perplexity: Application to English, Portuguese, and Spanish”. In Natural Language Engineering, 1-22, 2019.
Pichel, José Ramom & Paulo Gamallo & Iñaki Alegria. “Measuring language distance among historical varieties using perplexity. Application to European Portuguese”. In Proceedings of the Fifth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2018), 145–155, 2018.
Pichel, José Ramom & Paulo Gamallo & Marco Neves & Iñaki Alegria. “Distância diacrónica automática entre variantes diatópicas do português e do espanhol”. In Linguamática 12, n.º 1, 117-126, 2020.